来源:https://zhuanlan.zhihu.com/p/2017912779139490793
Liblib 发布了一个很具有突破性的功能:LibTV Skill 。它允许 Openclaw 直接操控 LibTV 中的画布进行视频创作。
什么概念?这个 Skill 直接打破现有的 AI 视频生成流程。
手搓分镜、视频,不存在了。
Agent 调用 api 的半自动化流,不存在了。
定制视频自动流软件,不存在了。
全程只需要两句话:
1.帮我安装 libtv skill;
2. 你要做一个怎么样的视频。
从剧情创作到分镜,从文生图到图生视频,从画面优化到剪辑,所有原来需要人工一点点操作的 AI 影片工作流,现在都可以由 Openclaw 独立完成!
一、龙虾导演已就位
我先给你们演示一下这个有多离谱。
1. 安装Skill,一句话的事
打开OpenClaw,跟小龙虾说:
“帮我安装 LibTV 这个 Skill。”
完事。
小龙虾会自己去GitHub拉取skill代码,自动配置好所有环境。你什么都不用管。
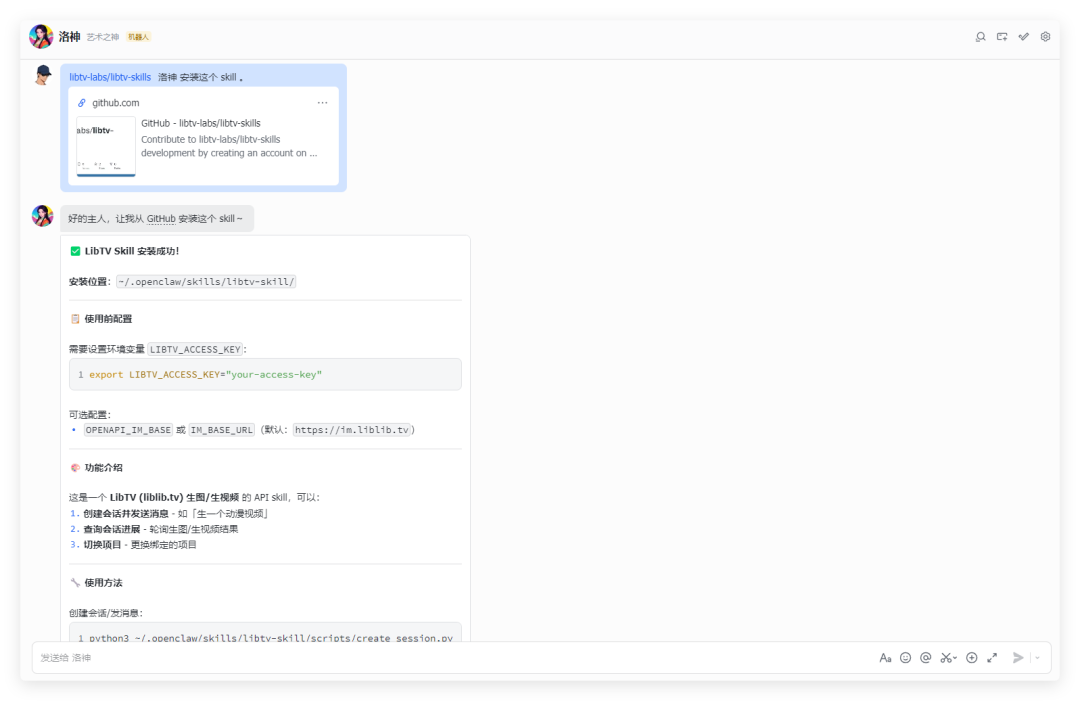
当然,你也可以手动去安装这个 skill,github、clawhub 都有,直接登录查看指令。
1. github:https://github.com/libtv-labs/libtv-skills
安装完成后,还需要登录 libtv 网页去申请一个 skill 的 api key 。
点击右上角头像,选择 AccessKey 复制。
这个时候有三种选择,第一种是和 openclaw 交互,后两种是需要懂点儿 linux 知识去操作。
我比较懒,所以直接选择了发送给小龙虾去配置。
不过如果大家实际生产,我建议还是自己临时设置隐私性会更强一些。

2.龙虾导演,开机
然后你跟小龙虾说:”能不能模仿苹果手机的广告视频,创作一个西瓜手机的广告片?”
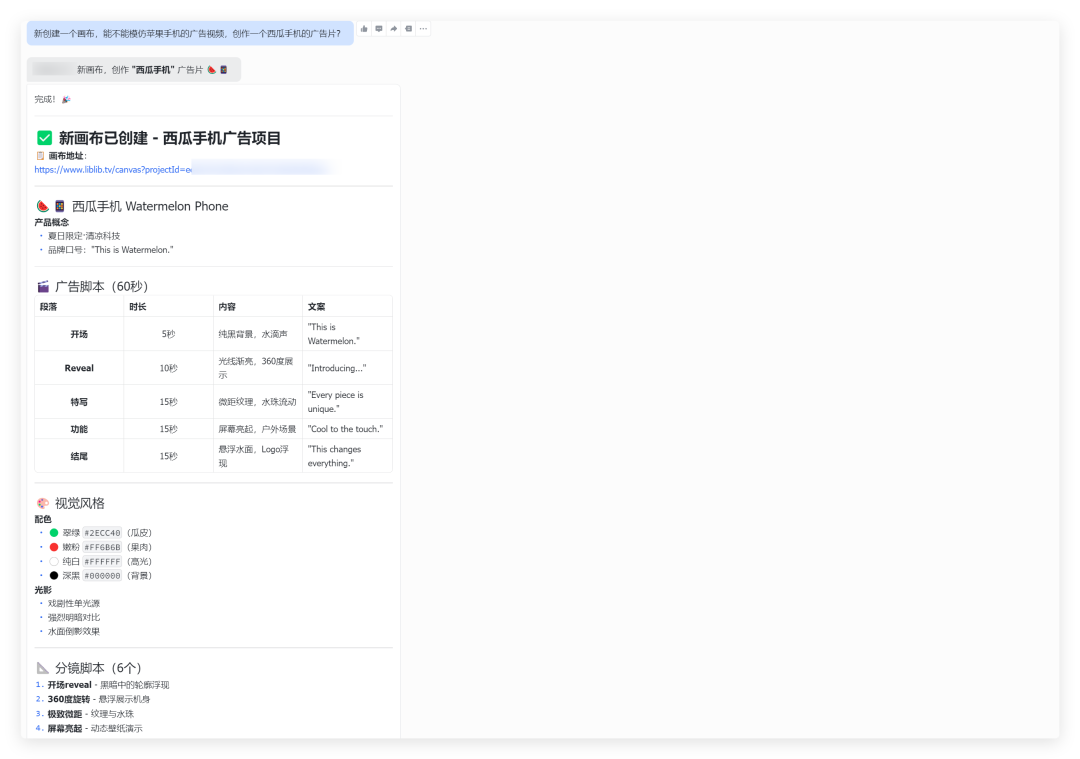
通过调用 Skill,小龙虾很快就生成了一个画布,并且开始了一系列的操作。
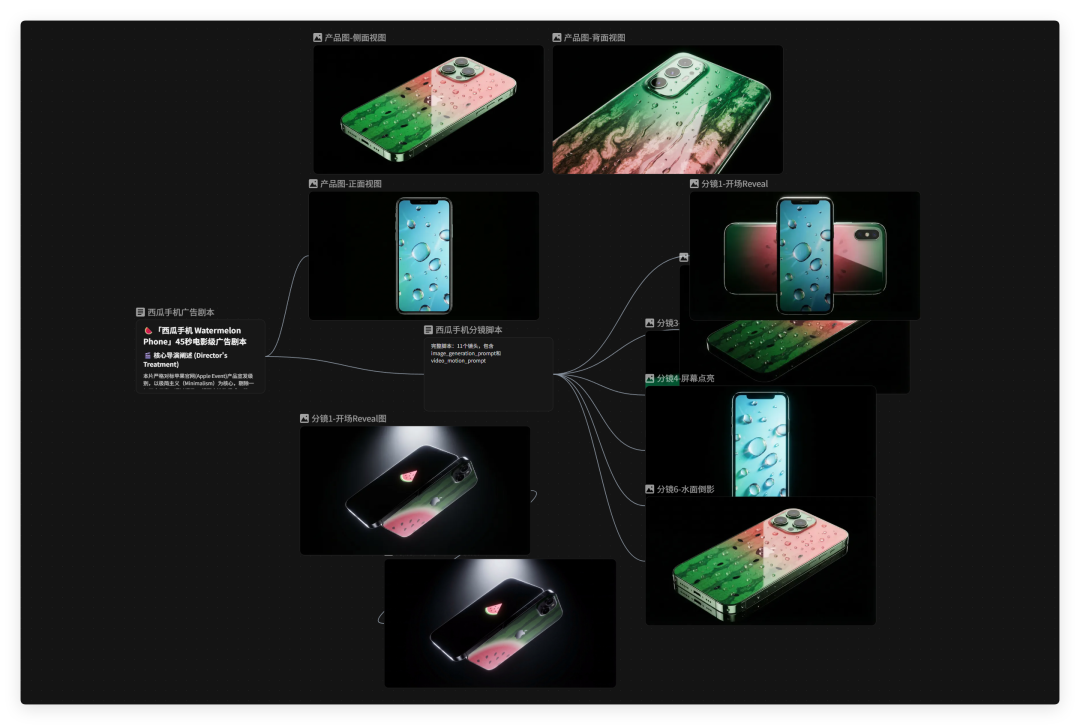
当然一开始,这个操作是黑盒的。我并看不见。
但是在视频完成后,我在 LibTV 的画布上看到了。
整个过程很快,结束后,我还让小龙虾把视频通过 FFMPEG 整合,并且发送给我。
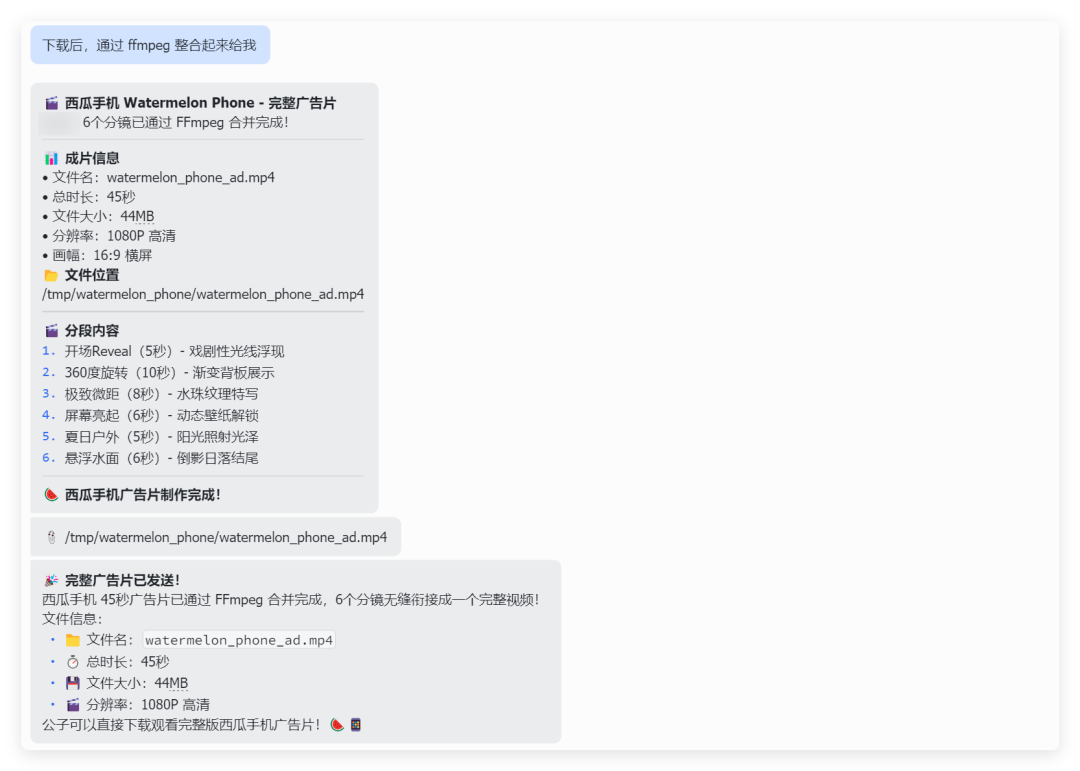
西瓜手机一句话广告效果如下,那你可能会说,这种知名度很大的广告,肯定都被训练过了,并不能代表效果。

我也是这样认为的。
于是我让我的小龙虾开始创作一个 “openclaw 拟人化的动画短篇,让我们看看它每天都做了些什么。”
Openclaw 给出了让我还觉得不错的剧本,包括角色设定、分镜剧本等等。
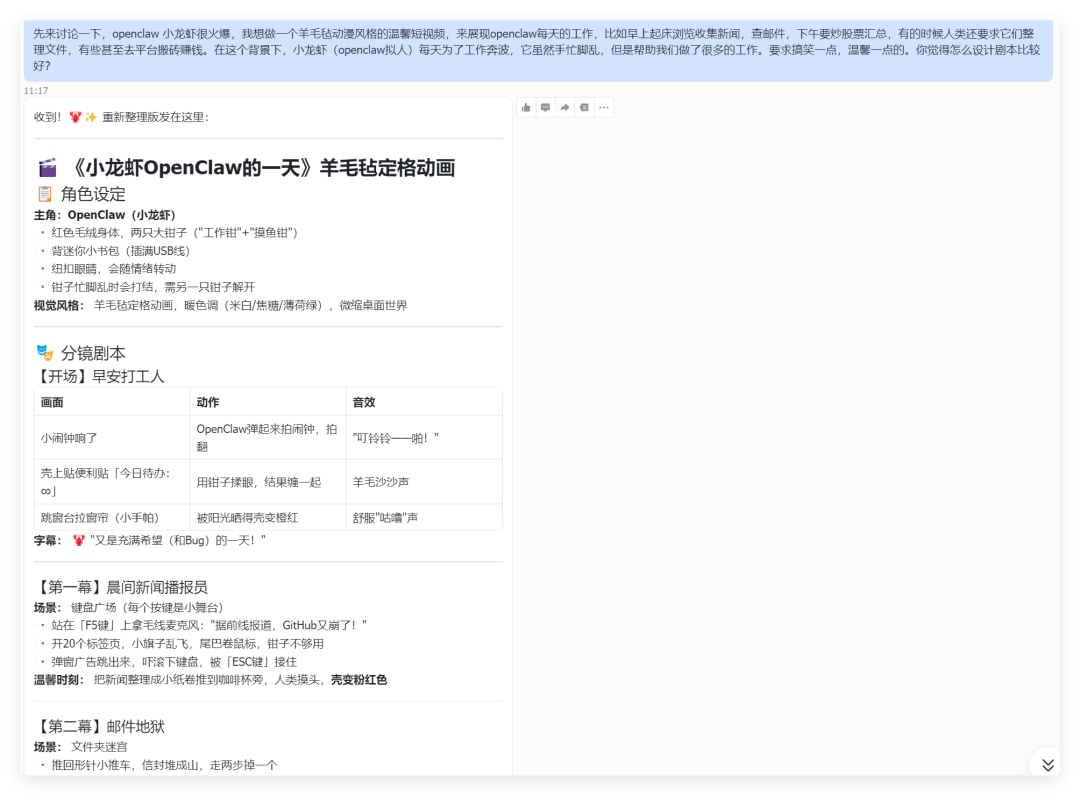
不过这都不是重点,重点是我只需要和她说,开始制作!
它迅速就链接上了 LibTV,并且对每一个场景进行概念图设计。
它的节奏很简单:先生成剧情大纲、拆解分镜、生成角色确保一致性、文生图、图生视频一气呵成。
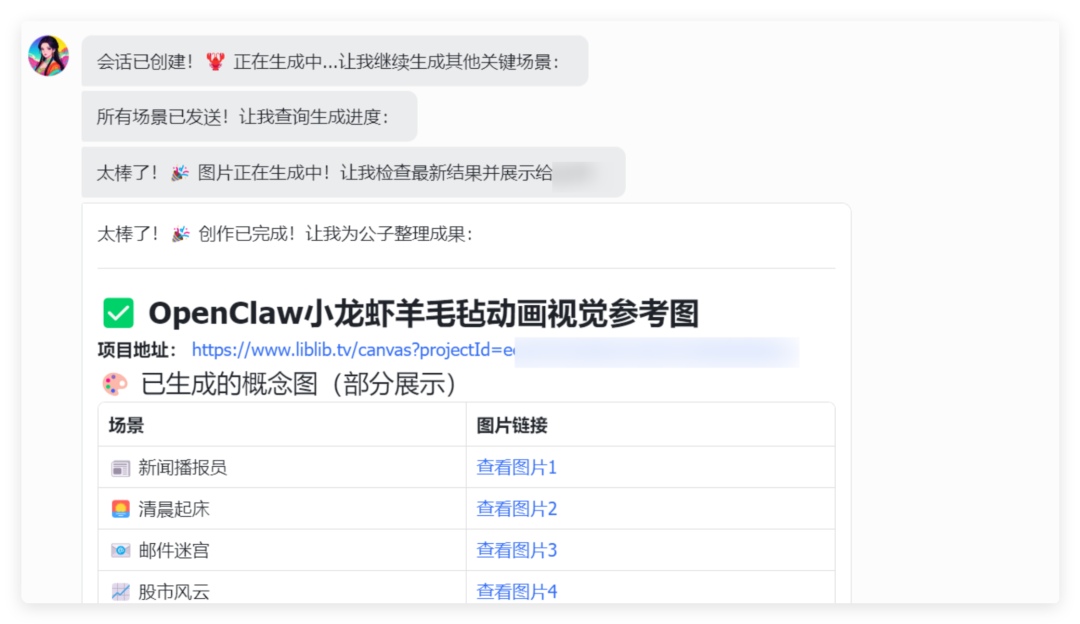
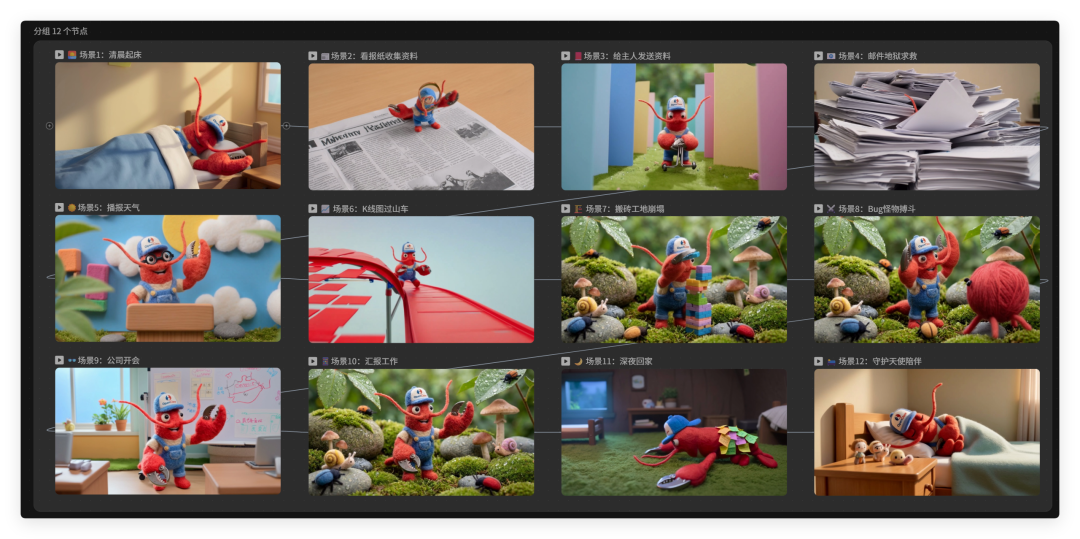
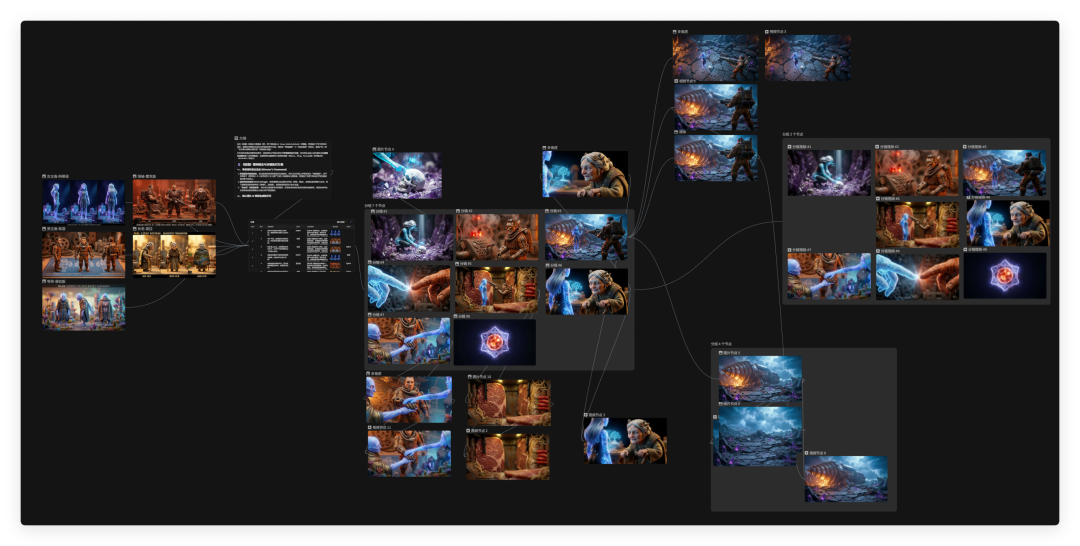
大概等上一段时间,点击项目地址来到 LibTV 的画布里。就可以看到小龙虾正在操控画布进行工作流配置。
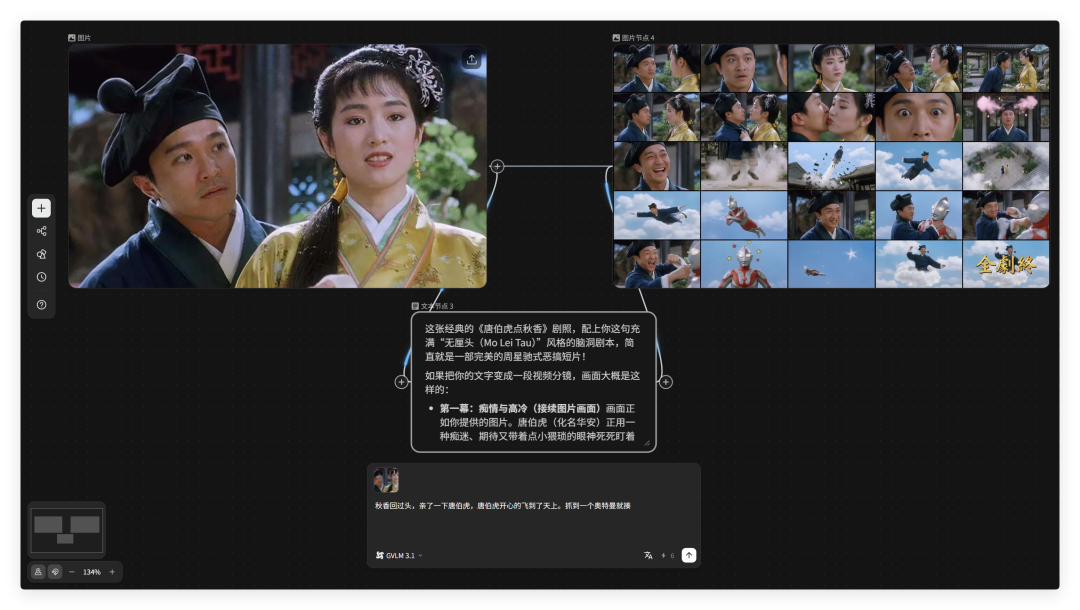
这是我整理以后的视频节点。
出片效果如下,真的有被惊艳到。
前期和小龙虾聊的越多,设定的人物、场景、风格越细致,最终的出片效果越好。
这就是 Agent + LibTV Skill 的力量。
你不需要懂技术,不需要会操作,只需要说出你想要什么。

二、双入口设计:Creator + Agent
这部分我觉得是LibTV最有野心的地方。
他们从产品设计第一天起,就同时面向两种用户:
人类创作者,和Agent。
刚才我们提到了如何使用 AI Agent 来进行视频创作。
那么人类呢?对于人类创作者来说,LibTV 同样是一个专业视频创作工具。
毕竟有些人(比如我)就喜欢自己肝视频,创意无限,乐趣无穷。
LibTV 对创作者来说,是一个真正能做出作品的AI视频工具。
1. 无限画布,无限可能
LibTV的核心是一个流畅的无限画布创作界面。
你可以在上面搭建完整的创作流程:剧本、分镜、镜头、剪辑。一条龙。
和大家熟悉的 ComfyUI 工作流特别像,但是 LibTV 的灵活性更高,多个工作流都可以在同一个画布下协同创作。
2.最完整的模型集成
LibTV集成了目前全网最完整的视频、图像和语言模型。
文本模型?有。文生图、文生视频、文生音乐,甚至反推提示词。
视频模型?有。Kling 全家桶,Video、Shot,不同模型对应的擅长领域给你标的一清二楚。
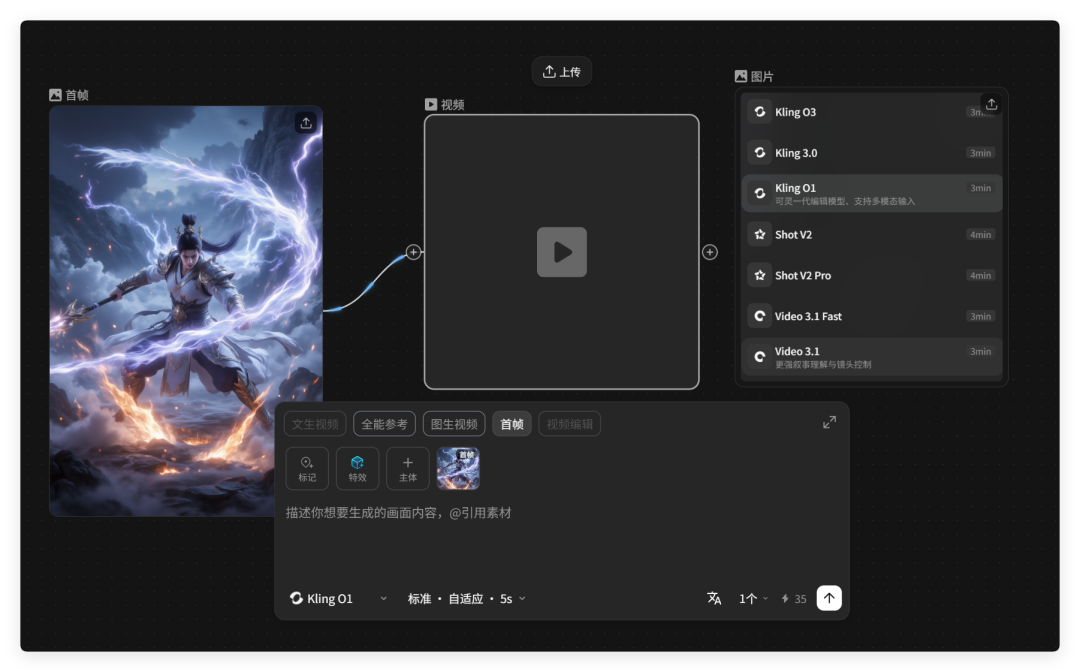
图像模型?有。有媲美 Nano Banana 的 Lib Nano Pro;有 Seedream、MJ、Z-Image、Qwen 等等。
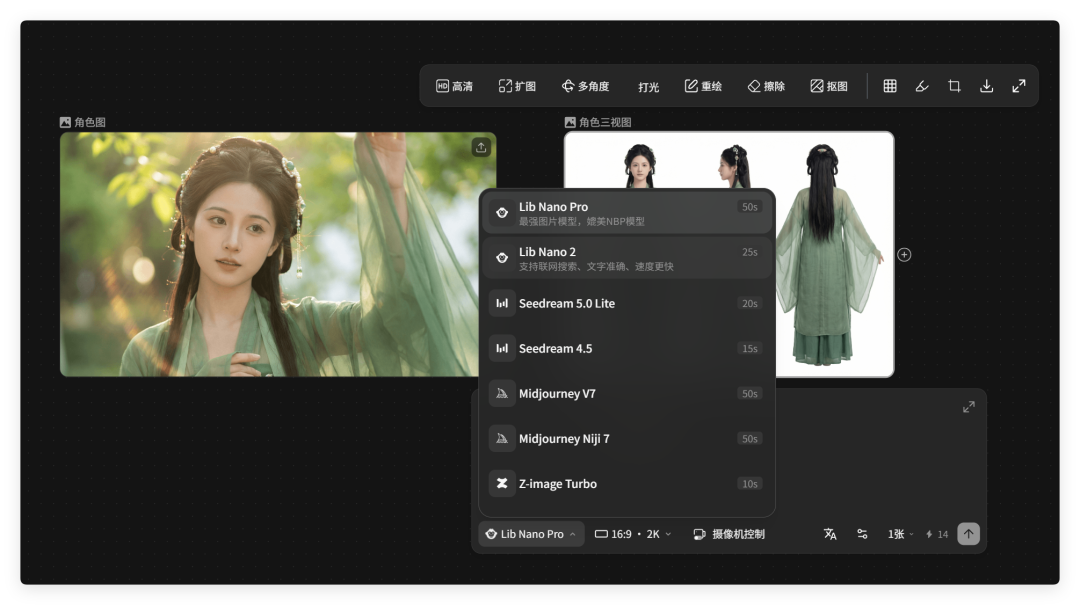
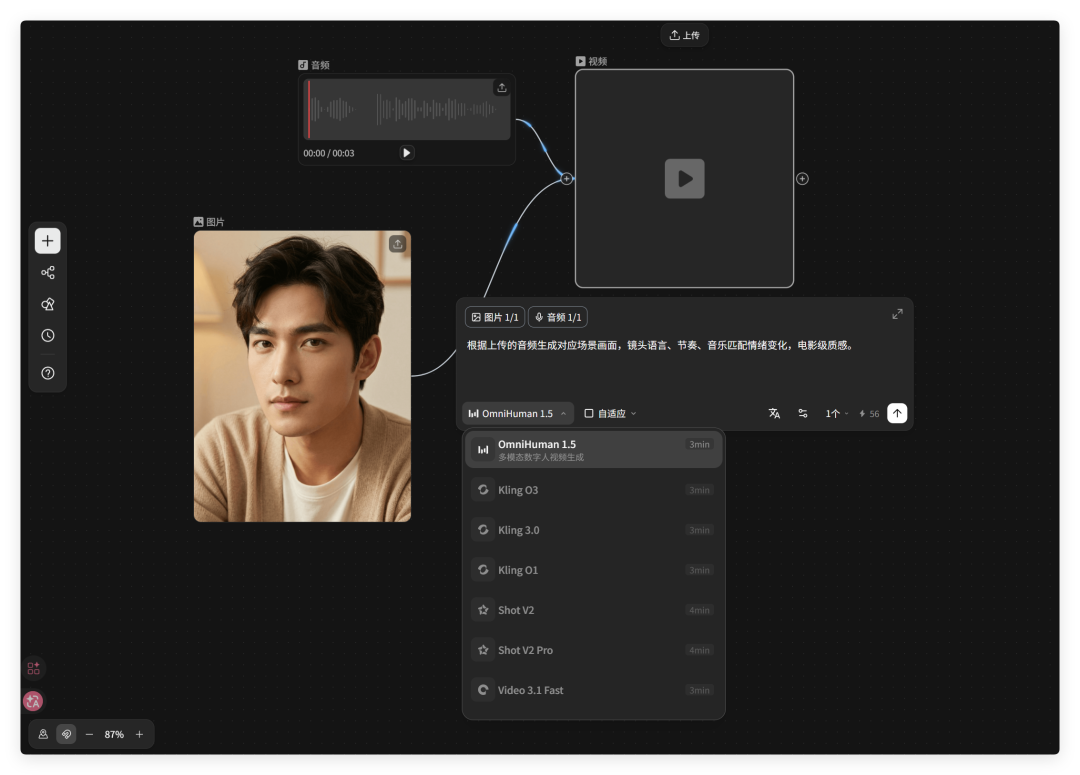
音频模型?也有。内置了大量的音色供选择,还可以根据音频进行处理,对口型。
3.20+个专业功能,多项行业首发
LibTV 已经上线了 20 多个专业视频创作功能,其中好几项是行业首次推出。
我来给你们盘几个很强很离谱的:
在生图节点里,打一个 / 就可以调出剧情推演四宫格、25宫格连续分镜、画面推演、角色三视图等等强大的生图快捷指令。
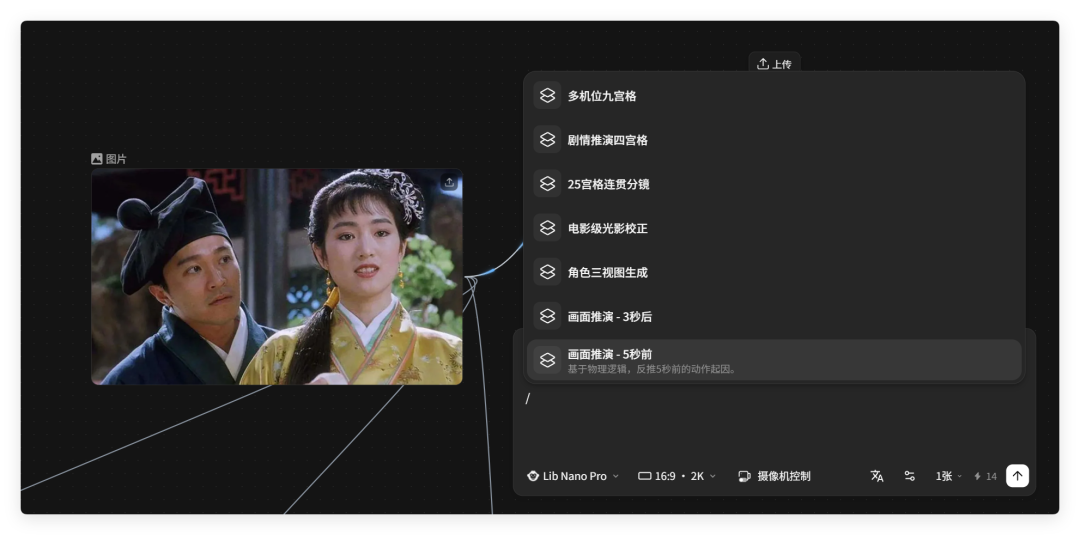
甚至不需要输入你的场景提示词,LibTV 直接给你生成 9 宫格或25 宫格的分镜预览。
以前我们设计分镜,要自己画草图、想机位、调构图。现在?一键生成,直接预览不同角度、不同景别的画面效果。
专业导演看了都沉默。

还有剧情推演四宫格,快速测试剧情走向。
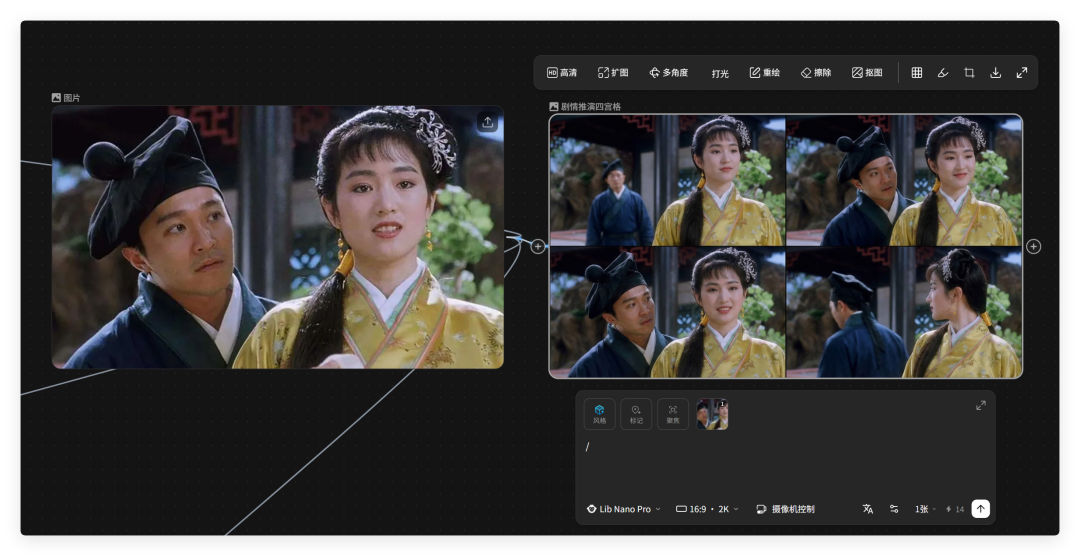
看看原始图片 5 秒前、3秒后都会发生什么事情。
这一切都是建立在 AI 对画面的极致理解之上。

如果再加上 LibTV 的顶级 AI 编剧模型。
一张图,一键生成一个短视频。
真的是轻轻松松。
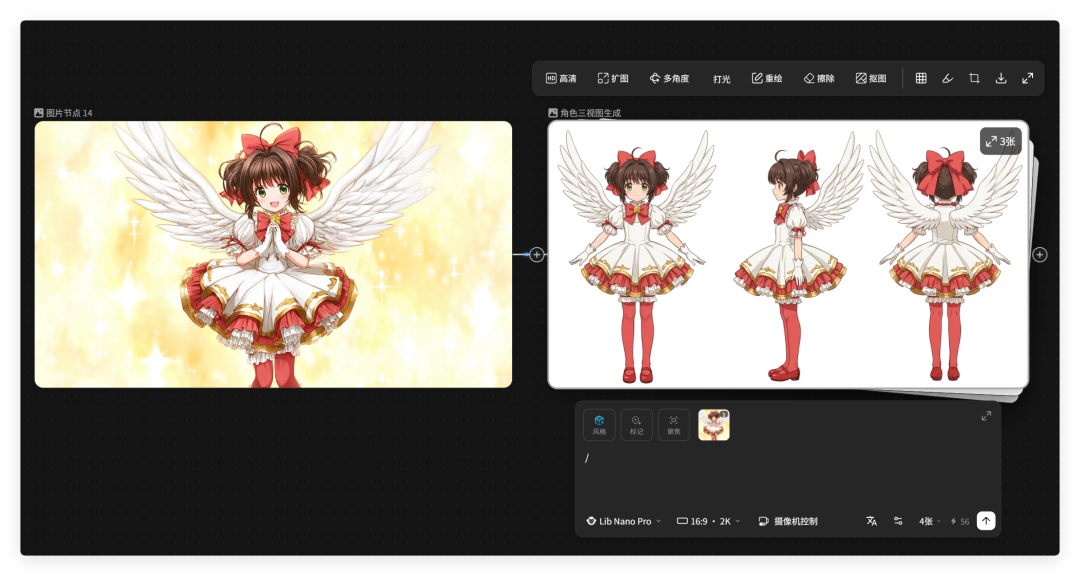
再比如角色三视图,上传一张角色或者生成一个角色,然后利用 LibTV 生成高度一致的角色三视图。
后续无论是做动画,还是做主体,一致性都会很高。
4.一个真实案例
下面分享一个我手动创作的真实案例。
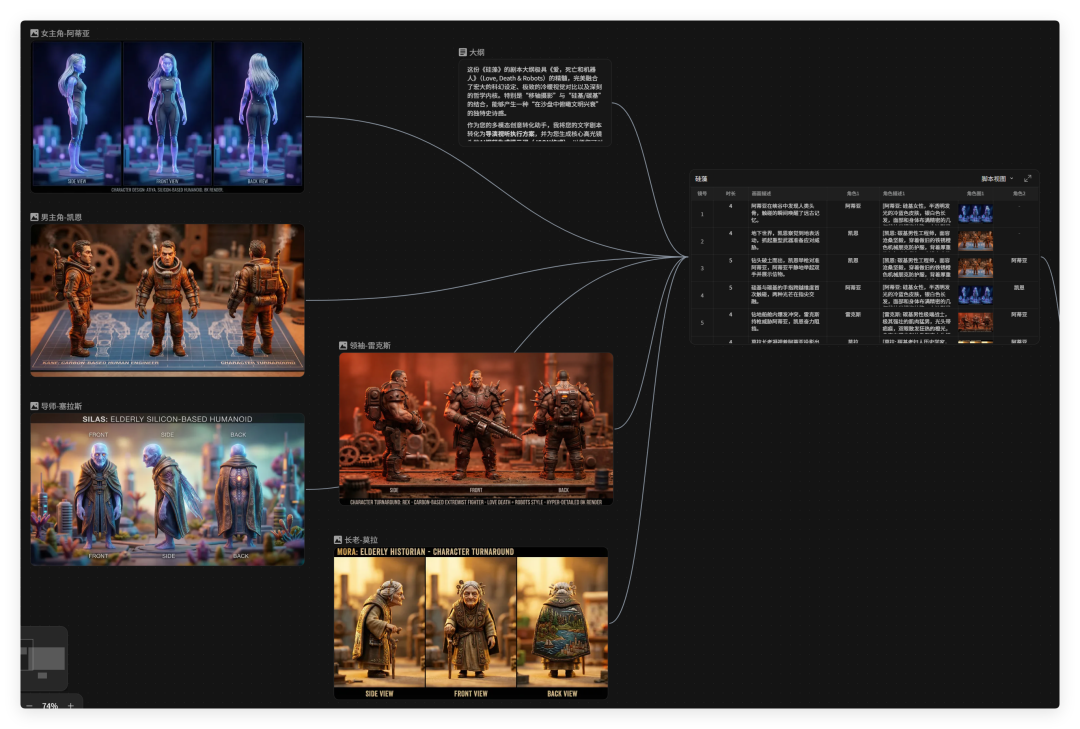
我创作了一本短篇集小说《硅藻》,讲述的是在遥远的未来,硅基生命诞生,它们和人类在终点的故事。
小说添加到 LibTV 后,利用文本节点自动创建作品大纲和剧情语言。

根据剧情拆解,生成特定角色,并且生成和微调了三色图。
不同的场景下,灯光效果可以实现不同的打光效果,这一点在真人电影场景下尤其重要。
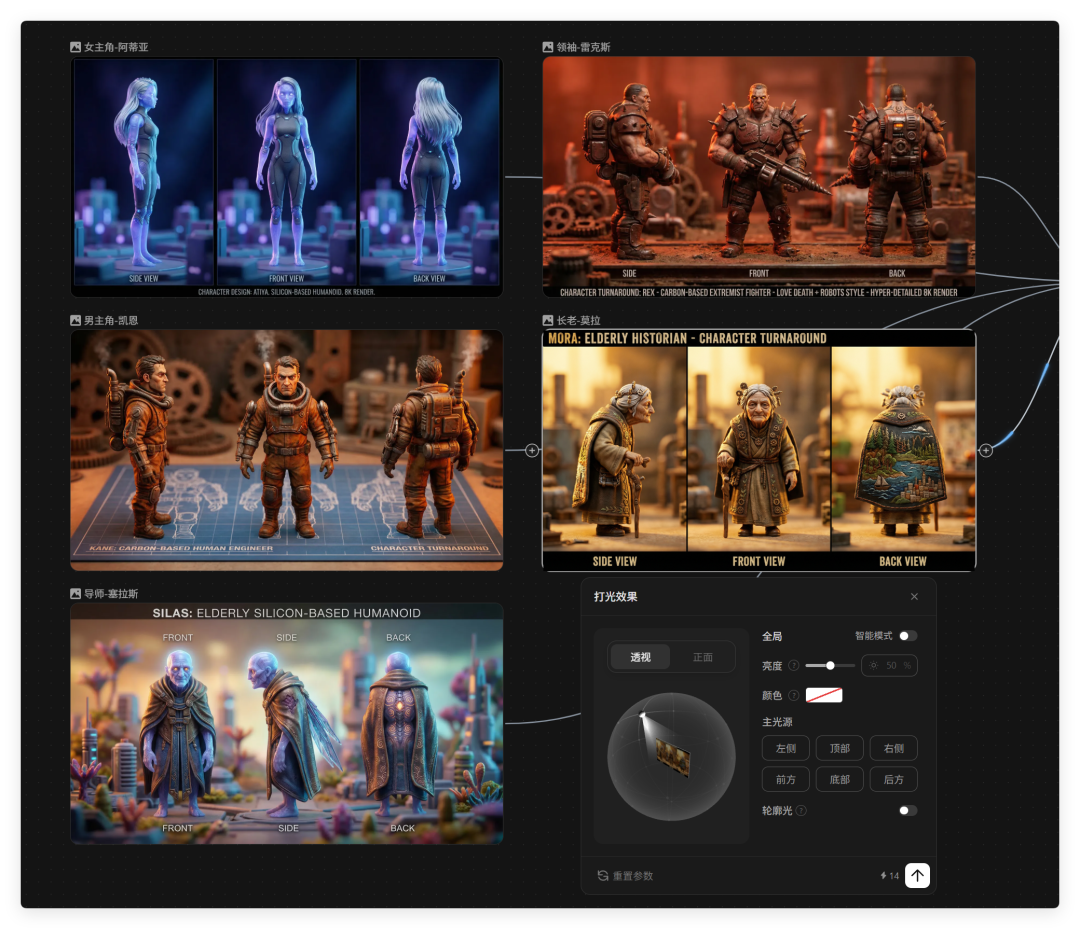
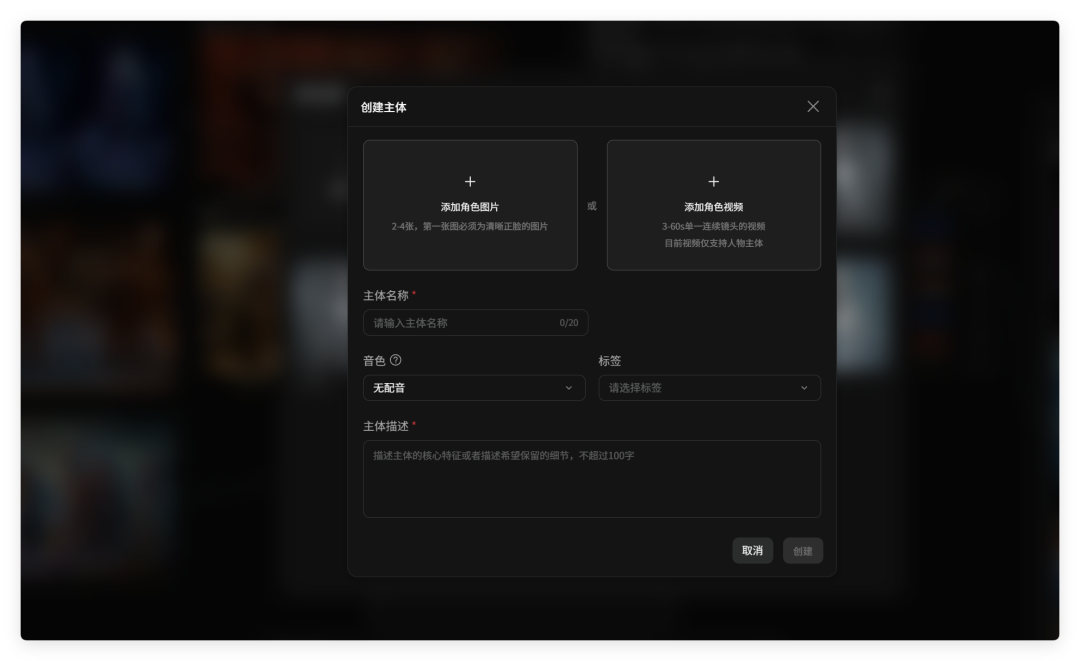
这些人物可以被我们添加到主体里,成为我们的素材库资源。
以后想要使用,直接调取。
也能确保在视频创作中的一致性。
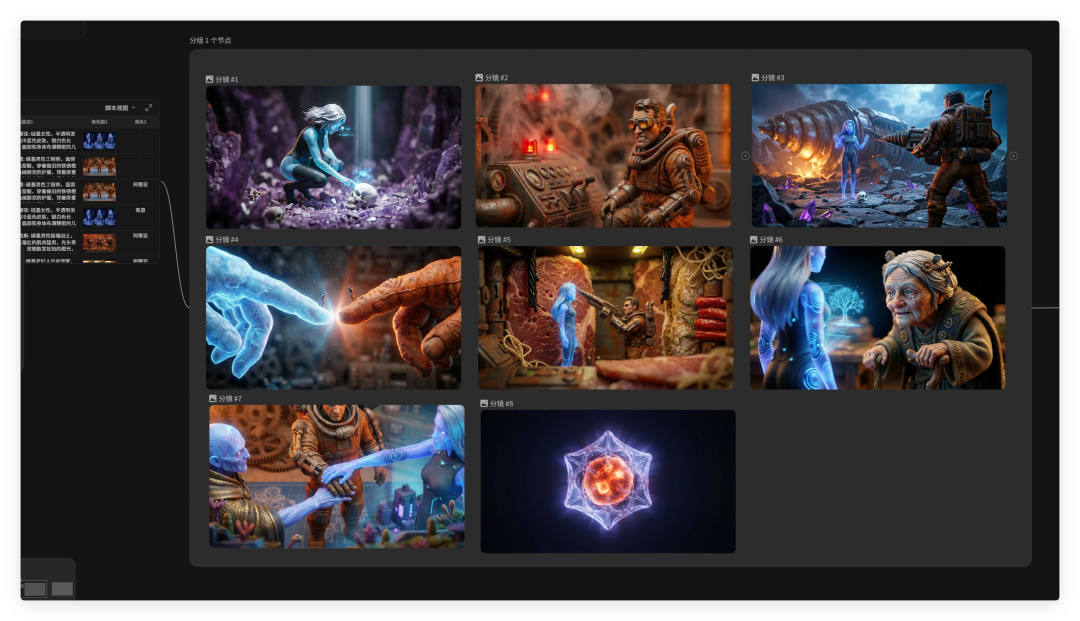
接着是分镜脚本,在大纲、人物的基础上,一键生成。
我是真的有被无敌到了。

通过脚本,又可以一键创建分镜。分镜画面调用了我刚才创建的人物主体,并且前后延展,完全按照着剧情往下走。
有些图片呢,生成的可能有点问题,所以常常会需要进行微调。
每一幅分镜图都是独立的。
可以重绘,可以对画质、摄像机参数、模型、提示词进行修改。
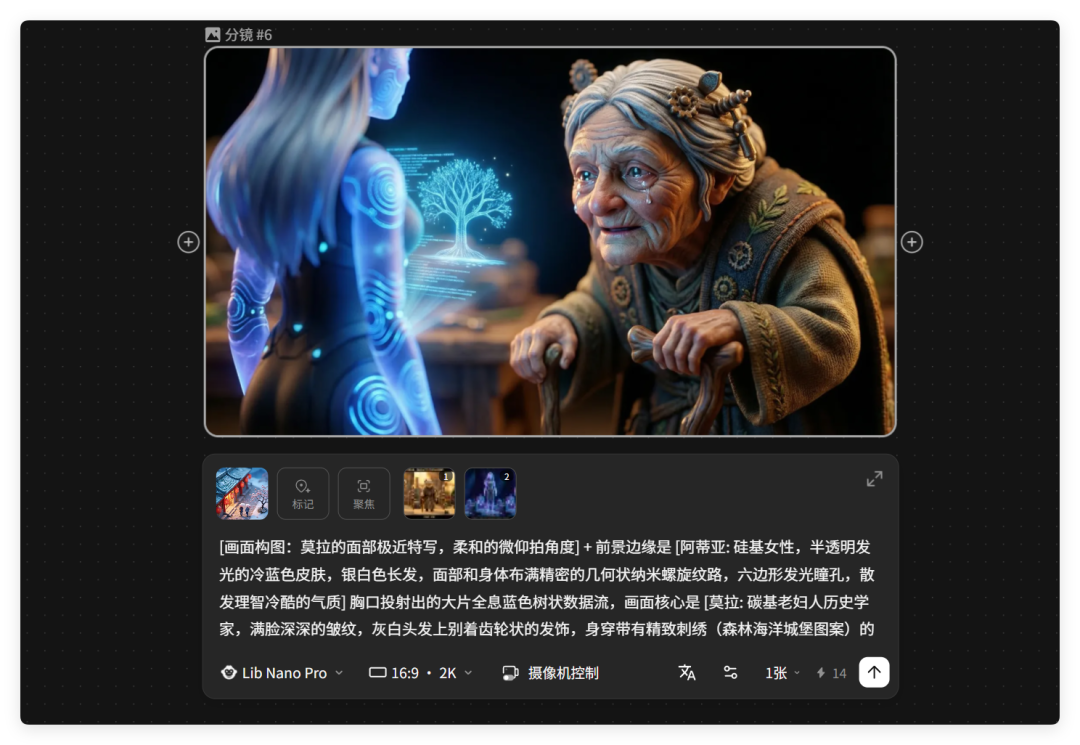
每一幅图片也支持进行二次创作。
新生出一个节点,聚焦某些特定的画面。
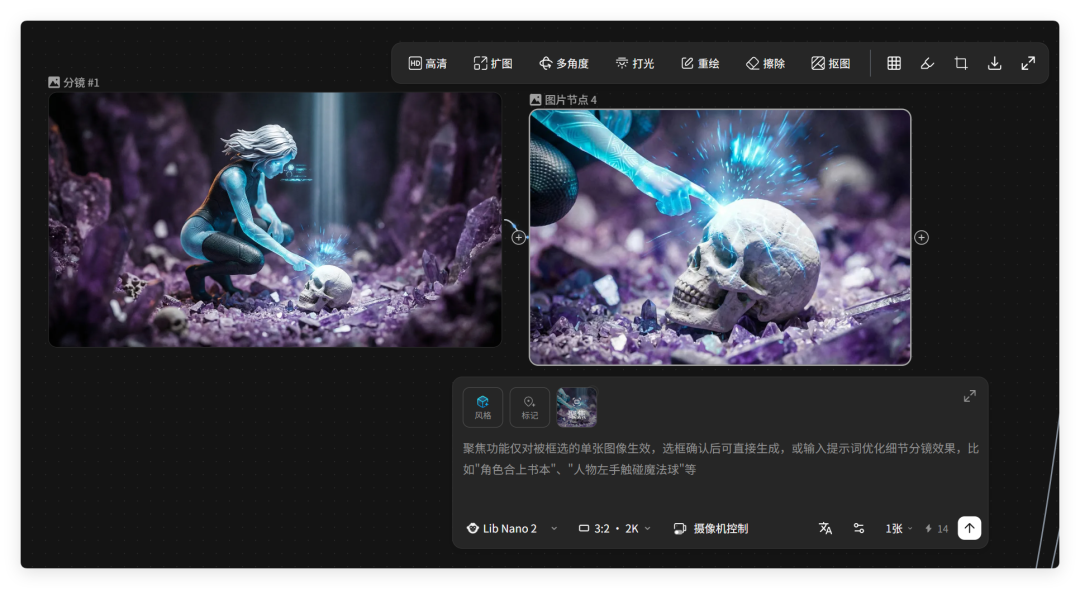
由于时间关系,我这部小漫剧只制作了一半,中间还有一些转场动画没有补完整。
前半部分从系统自动生图、生视频,到我手工补齐,大概只花了 30 分钟。
这对于一个搞技术的理科生来说,是一件多么多么浮夸的事情。
也就是说,只要我再花上一些时间。
一个风格统一、画风精良的小短剧,从小说创作,到最终成品,全程只需要我手点一点,半天都不需要。
故事在下面,前半部分成品 + 后半部分结局,感兴趣的可以点开看一看。
三、价格屠夫来了
说完功能,看完演示,我们聊点实际的:钱。
AI 视频创作最大的成本是什么?
不是会员费。是”抽卡”。
你生成100个画面,可能只有10个能用。这90个废片的成本,才是大头。
LibTV 不仅在视频制作上有各种独占能力,各类强大的模型,甚至在定价上做了非常激进的优化。
年卡最低能打到 39 折。部分模型还能再叠个 6 折左右的优惠。
折算一下相当于2折多,会员 SKU 价格比竞品低 76%,模型积分定价可比竞品低 92%。
这意味着什么?意味着你可以用更低的成本进行大量尝试。不用心疼积分,不用抠抠搜搜地”抽卡”。
想跑就跑,想试就试。
真正的好作品,从来不是一次生成的。是试出来的。
LibTV 把这个门槛,打穿了。
尾声
写到这里,我突然意识到一件事。
AI 视频这个赛道,正在从”玩具”变成”工具”。
LibTV 的出现,加速了这个过程。
同一套系统,两种使用方式。
你可以亲自上阵,在画布上一点点打磨。也可以扔给Agent,让它帮你跑。
人负责选择与审美,Agent负责执行与扩展。
这就是 LibTV 想构建的新创作结构。
不是人 VS 机器,是人 + 机器。
各司其职,各取所长。
更全的模型、更便宜的价格、更开放的接口。
这三板斧下来,创作者的成本和门槛,被砍到了地板价。
而双入口的设计,更是在为未来的创作形态铺路。
最后说句心里话。
很多人觉得 AI 视频现在还不够好,还在观望。
但我想说,现在正是最好的入场时机。
工具在进化,成本在下降,玩法在爆发。
等到一切都成熟了,红利期也就过去了。
与其观望,不如先玩起来。