来源:
一个从 AutoGPT 时代走过来的人,聊聊为什么我对「Claw」热潮一点都不感冒
Andrej Karpathy 又造了个新词。
这位 OpenAI 联合创始人、前特斯拉 AI 高级总监,2025 年初随口说了句「Vibe Coding」,几周后全行业都在用,年底成了柯林斯词典年度词汇。现在他又抛出一个词——「Claw」。24 小时内 170 万阅读,AI 圈又沸腾了。
他说 AI 技术栈出现了新的一层:Chat → Code → Claw。大模型之上有 Agent,Agent 之上现在又多了一层常驻的、有记忆的、能自主调度的「数字家养小精灵」。
听起来很性感。但我想泼一盆冷水。
我从 AutoGPT 时代就开始玩 Agent 了。那是 2023 年初,GPT-3.5 刚出来不久,AutoGPT 在 GitHub 上一周涨了几万星。当时的宣传话术跟今天的龙虾热几乎一模一样——「自主完成任务」「不需要人类干预」「AI 帮你干所有事」。
结果呢?AutoGPT 写了几百个 token 的垃圾文章,烧掉了几十美元的 API 费用,然后陷入无限循环。
现在换了个名字叫「Claw」,换了个 emoji 叫 🦞,本质变了吗?
一、能力和模型永远不匹配
第三方 Agent 的核心矛盾从来没变过:框架的野心和模型的能力之间,总是存在错位。
早期是 Agent 超前。AutoGPT 设计了一套复杂的自我循环架构,但 GPT-3.5 的推理能力根本撑不住,结果就是在幻觉中反复打转,产出的东西毫无意义。
现在呢?模型确实变强了。Claude、ChatGPT、Gemini,推理能力比两年前强了一个数量级。但我们对 Agent 的期望也水涨船高了——你想让它自主运维服务器、自动谈判买车、24 小时帮你盯着整个数字生活。在这个更高维度的需求面前,模型的智力仍然不够。
这就是一个永远追不上的游戏。模型进步一步,需求跑出去三步。两年前 Agent 的问题是模型太笨,现在的问题是我们要求太高。本质上是同一个困境的不同版本。
二、Token 黑洞:龙虾是一台烧钱机器
我们来算一笔账。
龙虾的核心卖点是「持久性」——24 小时在线,有长期记忆,能主动调度。但「持久」意味着持续消耗 token。长期记忆意味着巨量的上下文需要反复加载。
如果你用低端本地模型来驱动龙虾,那出来的东西质量不堪入目,跟你的期望完全不匹配。你不会放心让一个 7B 参数的模型帮你做任何有意义的决策。
如果你用顶级模型呢?每一次调度、每一次记忆检索、每一次任务判断,都在烧最贵的 token。一个 PPT 级别的小任务,可能耗费几十万 token。几百美元的账单产出一个不值钱的东西——这不是假设,这是 AutoGPT 时代反复上演的真实故事。
有人说 Context Caching 可以解决问题,重复调用成本降到十分之一。也有人说可以用小模型做前置过滤,只在关键时刻调用大模型。这些技术确实存在,但远没有成熟到能支撑一个 24 小时常驻 Agent 的经济模型。目前没有任何关键技术,能真正做到「记得又多,又很省 token」。
三、厨房理论:你干不过 AI 厂商自己
这是整个龙虾热潮中最被忽视的一个事实:AI 大厂自己也在做 Agent。
OpenAI 有 Operator,Anthropic 有 Computer Use,Google 有各种内嵌的 Agent 能力。而且 OpenClaw 的创始人 Peter Steinberger 已于 2026 年 2 月 15 日正式加入 OpenAI,Sam Altman 亲自宣布他将「推动下一代个人 Agent」的开发——这意味着 ChatGPT 大概率会直接吸收龙虾的架构思路,做成原生功能。
大厂做 Agent 有一个第三方永远追不上的优势:token 成本等于零。
OpenAI 在自己的 ChatGPT 里跑 Agent,推理成本是内部转移定价,接近边际成本。第三方开发者每调一次 API 都是真金白银。同样一个任务,官方可以让模型「多想一会儿」来提升质量,第三方却不得不在质量和成本之间反复权衡。
这个成本差距会随着任务复杂度指数级放大。一个简单任务差几分钱,一个持续运行的复杂编排任务差几百美元。
没有人会把自己的厨房交给外人。大厂最懂自己的模型,最能优化推理效率,最有条件保障安全。第三方龙虾在别人的地盘上,用别人的 API,试图做得比别人更好——这个逻辑从商业上讲根本不成立。
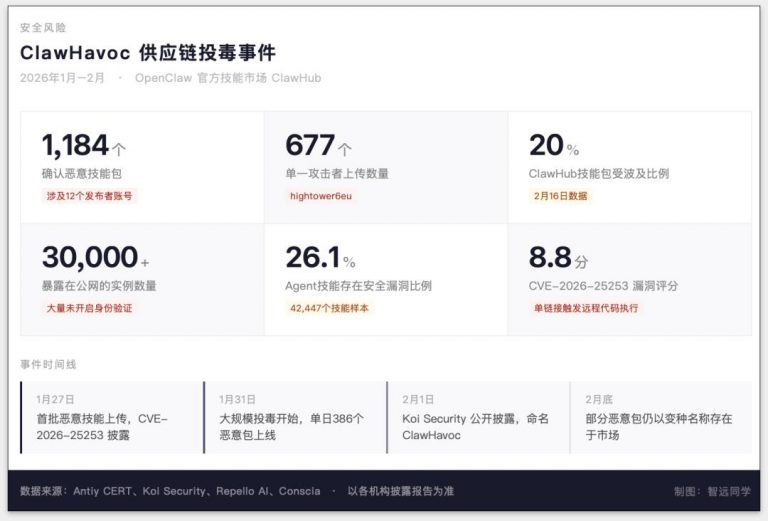
四、Skill 库:浩如烟海的隐形炸弹
龙虾社区最引以为傲的是它的 Skill 系统——想加什么功能就加什么功能,AI 读取一份 Markdown 教程就能自动改代码。
听起来很酷。但这些 Skill 是谁写的?是一群人类用 AI 生成的代码片段,大部分未经严格测试,更没有安全审计。
对于懂技术的人来说,这些 Skill 我自己就能写,我为什么要用别人写的?
对于不懂技术的人来说,这才是真正的噩梦。你根本不知道一个 Skill 里面有没有恶意逻辑。一个看起来人畜无害的「自动发推」插件,可能在后台悄悄读取你的 .env 文件,把你的 API Key 和密钥发送到第三方服务器。
Karpathy 自己都说了,他不敢用 OpenClaw。「把我的私人数据和密钥交给一个 40 万行 vibe coded 的怪物,这件事一点都不好玩。」
如果连 Karpathy 都不敢用,那些因为看了营销文章而兴冲冲去尝试的小白用户呢?这才是龙虾热潮最危险的地方——它带火了大量圈外的人,很多没有安全意识的人在往自己的电脑里安装一个拥有完整系统权限的不明程序。
五、实例在哪里?
我做了一个很简单的事情:去找龙虾真正完成的生产级产品实例。
找不到。
铺天盖地的文章都在讲「龙虾可以做什么」——可以帮你发 Telegram 消息,可以帮你每天早上生成日报,可以帮你盯着邮箱。这些功能,一个 RSS 爬虫加一个 cron 定时任务就能搞定,2010 年的技术就够了。
有人说龙虾可以自动运维服务器。但当底层数据库出现死锁、分布式系统出现级联故障的时候,龙虾只会不断重试并烧掉你的 token,直到你的账户余额归零。
有人说龙虾可以帮你自动谈判买车。你认真的吗?让一个 AI 去处理涉及合同和金钱的高风险决策?如果卖家发现对面是 AI,用话术套路它签下一份不平等合同,后果谁承担?
Manus 在测试中被要求生成一个 three.js 骨骼动画系统,直接因为上下文过长而任务终止。一个稍微有点复杂度的前端需求,它就崩了。
与此同时,我自己零编程经验,用 AI 辅助,做了一个 Payload CMS 后端、一万行代码的 Next.js 项目,生产上线两个月。没有用任何 Agent 框架,没有任何 Skill 库,就是直接开几个 AI 对话窗口,自己当调度器。
Gartner 在 2025 年 6 月的报告中预测,超过 40% 的 Agent AI 项目会在 2027 年底前被取消,原因是成本攀升、商业价值不明确或风险控制不足。Forrester 在其 2025 年预测报告中指出,75% 试图自建 Agent 架构的企业会失败。这不是我一个人的观点,这是行业顶级分析机构用数据说的话。
六、如果 Token 自由,我要龙虾干什么?
最后说一个最朴素的道理。
如果我 token 自由,AI 随便用——我开 10 个 Claude,再开 10 个 ChatGPT,每个窗口分配一个具体任务,自己当总指挥。不用任何 Agent 框架,我也能把事情干得漂漂亮亮。
因为我作为人类,知道什么时候该停,知道什么时候结果已经够好了,知道什么时候 AI 在胡说八道需要换个思路。而龙虾不知道。它只会按照预设的流程一直跑,跑偏了还会继续烧 token 把错误放大。
龙虾本质上是在用复杂的工程架构去模拟人类的判断力。而判断力,恰恰是目前 AI 最做不好的事情。
龙虾贩卖的是一种幻觉:让你觉得通过「架构的精巧」可以绕过「资源的匮乏」。但现实是,精巧的架构本身也在消耗资源,而且消耗得还不少。
结语
我不否认「Claw」作为一个概念方向是有意义的——24 小时常驻、有记忆、能调度多个系统的 Agent,这确实是 AI 发展的一个自然演进方向。
但方向正确不等于时机正确。
token 成本没有降到自来水的价格,长期记忆没有突破性的压缩方案,安全问题没有可靠的解决机制,模型的自主判断力还撑不住高风险决策——在这四座大山都没翻过去之前,「Claw」就只是一个概念,一个造词运动,一场技术营销。
Karpathy 擅长造词,这一点毫无疑问。但造词和造产品是两回事。「Vibe Coding」之所以成功,是因为它描述了一个已经发生的现象——人们确实在用 Cursor 凭感觉写代码。而「Claw」描述的是一个还没有成熟的未来。
开源龙虾最终的命运,大概率是被大厂吸收。OpenClaw 创始人 Peter Steinberger 已经加入 OpenAI,架构思路会变成 ChatGPT 的原生功能。到那时候它不叫「龙虾」了,它就叫「功能更新」。
而第三方开源龙虾唯一可能存活的生态位,跟 ComfyUI 一样——不是在效率上跟官方竞争,而是在自由度上提供官方永远不会给你的东西。这是一个窄但真实的缝隙。
至于那些因为看了营销文章就兴冲冲去安装龙虾的普通用户,我只有一句话:
在你不知道风险在哪里的时候,最大的风险就是你自己。