

来源:https://zhuanlan.zhihu.com/p/2006510505351733880
Seedance 2.0 发布的时候我手痒了,想试试现在的AI视频生成到底能做到什么程度。于是花了大概一周时间,从零开始摸索,最终做出了一部1920年代克苏鲁风格的短视频。
这篇不是教程,是制作手记。记录真实的流程和真实的血泪教训。
我用了哪些工具
先摊牌,整个项目的工具链长这样:
- 即梦 / Seedance 2.0 — 视频生成的绝对主力。关键帧生成和视频片段都靠它。
- ComfyUI — 辅助角色,负责生成一些静态图(过渡帧、角色参考图),以及后期用FlashVSR做视频超分到1080p(虽然最后上传的也不是超分后的还是原生720p)。
- DeepSeek — 把剧情大纲丢给它,让它帮忙拆分镜。AI写分镜比我自己想快多了。
- iopaint — 去水印,用的LaMa模型,只处理静态图。
- demucs — 音频分离,把背景音乐和人声拆开,方便后期混音。
- ffmpeg — 万能瑞士军刀。抽帧、格式转换、视频拼接都靠它。
- iMovie — 最终剪辑。没用Premiere,因为这个体量iMovie够用了。
一个人的流水线,没有专业设备,没有本地显卡(用的AutoDL云GPU按小时租)。


从文字到视频的完整流程
整个制作流程大概是这样的:
第一步:剧本 → 分镜
我先把故事整理成一段完整的剧情描述,然后丢给DeepSeek,让它按照”镜头号-景别-画面描述-时长”的格式输出分镜脚本。AI生成的分镜不能直接用,但作为起点省了很多时间,我在它的基础上调整合并。
第二步:分镜 → 镜头组
12个分镜太碎了,逐个生成视频既贵又难保证连贯性。我把相邻的、场景相同的分镜合并成”镜头组”,最终EP01压缩成5组。每组内部的镜头共享同一个视觉基调,组与组之间允许有风格跳跃(后面用过渡帧解决)。
第三步:镜头组 → 视频片段
这是最耗时的环节。每个镜头组的制作流程大致是:
- 用即梦生成关键帧(静态图)
- 确认画面满意后,用Seedance 2.0把关键帧转成视频片段
- 用ffmpeg抽取视频尾帧,作为下一个镜头的起始帧,保证画面衔接 (也不是每个镜头都这样操作)
第四步:组装 → 成片
所有片段在iMovie里拼接,加转场、配乐、字幕。音频用demucs分离处理后混入。
听起来很顺畅对吧?实际上每一步都有坑。
踩过的坑(和活下来的经验)
手部动作:当前AI视频的阿喀琉斯之踵
Seedance 2.0可以说是目前全球范围内最强的视频生成模型之一了。但即便如此,涉及到精细的手部动作——拆信封、展开信纸、穿衣服——依然会翻车。
这里说的不是早期那种”手指融在一起”的生成质量问题,那个行业基本解决了。现在的问题是:AI听不懂你描述的精细动作。比如”用拆信刀拆开封蜡”,模型不理解这个动作的完整物理过程——刀尖插入封口、沿边缘划开、蜡封断裂。它的训练数据里可能根本没有足够的样本来匹配这个动作序列,于是就用一个最简化的”刀划一下→信封直接打开”糊弄过去。展开信纸、穿衣服也是同样的问题。而且这个能力还不稳定——我有一段穿衣的镜头,第一次生成完全没问题,第二次就变成衣服直接”闪现”到身上。说明模型对这类动作有一定理解,但不深,结果好不好基本靠运气。


我的解法: 别跟AI较劲。碰到复杂手部动作,要么用prompt强制在动作发生前切镜头(比如”镜头切到面部特写”),要么生成完了在剪辑阶段把穿帮的帧剪掉。这其实跟真人电影的做法一样——手部特写从来都是单独拍的,没人指望一个长镜头搞定所有动作。
Prompt的”精度悖论”
这是我花了最多积分才悟出来的教训。
Seedance的能力很强,强到如果你的prompt写得太复杂,它会试图同时满足所有描述,结果顾此失彼。我有一段让哈维(主角)拿着伞推门出去,结果AI给了我一个右手推门、左手拿伞的别扭姿势——伞像是焊在手上的,手握着拳,伞把夹在指缝之间,完全不是正常人拿伞的样子。模型要同时处理两个手部动作,推门那只手勉强搞定了,拿伞这只手就只能糊弄一个”手附近有伞”的最低限度解。
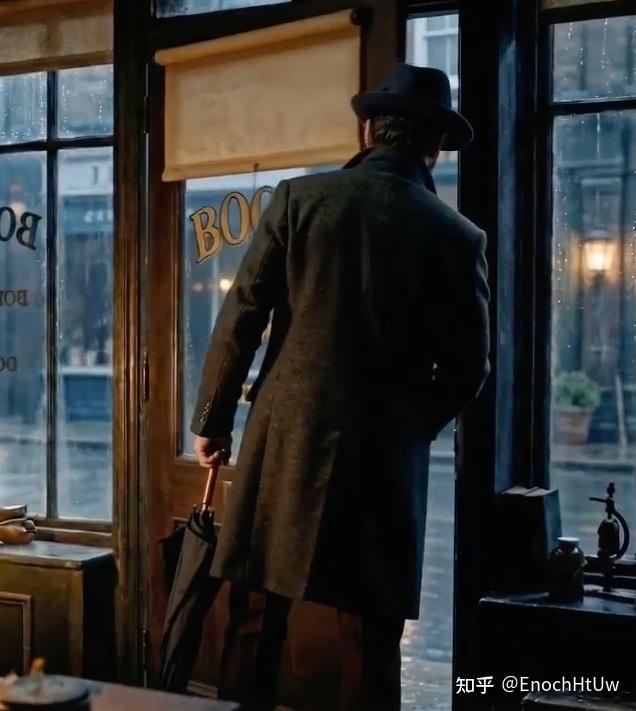
但如果你描述太少,它又会自己”脑补”。有一段我只写了”哈维出门打伞”,它直接把手里的公文包变形成了一把伞——因为在模型的特征空间里,”手持物体”的不同类别可能离得很近。
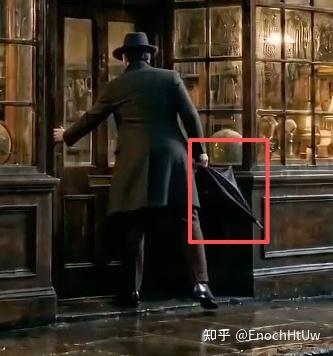
核心矛盾: 当前的视频生成模型有足够的生成能力把画面做得很精细,但没有足够的逻辑推理能力来理解动作的因果关系。能力越强,”自作主张”的幅度越大。
实战策略: 每段视频只给一个核心动作。”哈维拿着伞推门出去”拆成两段——”哈维推开门走出”和”哈维撑伞走入雨中”。道具交互要么写死具体哪只手(”右手握伞柄”),要么干脆别提,让剪辑解决。
人物出场:别让AI思考”从哪儿来”
有一个镜头需要哈维从店内走出来。我试了各种描述——”从书架旁走出”、”从画面左侧的位置出现”,甚至直接在图上涂红标记出场位置。结果AI每次都让他穿墙而出。

后来我把prompt改成”从画面的最左侧出现”,一次就成了。
想了很久才想明白为什么:Seedance会从起始帧里推断空间结构——哪里是墙、哪里是门。当你说”从书架旁出现”,它看了看起始帧,发现书架那边是一面实墙,”这儿没门啊”,于是就去找最像门的地方——墙壁本身。
而”从画面最左侧出现”之所以有效,是因为画面边缘在模型的认知里是天然的”入口”——画外空间。人从画外走入画内,这在电影里太常见了,训练数据里有海量样本,模型不需要做任何空间推理就能执行。
经验: 让人物从画面边缘入画,而不是从场景内某个位置”凭空出现”。前者是模型见过无数次的自然运镜,后者需要模型理解场景的物理结构——而这恰恰是它的弱项。
视频延伸只能”顺着走”
EP01结尾我想加一个悬念镜头:主角走远后,镜头翻转,露出一个一直在暗处监视的神秘人物,然后推进到他的眼部特写。
一个prompt,三件事:镜头翻转、新角色出现、推进特写。反复生成了十几次,全部失败。
原因是视频延伸的本质是时序外推——”根据当前画面,下一帧最可能是什么”。它擅长”顺着走”,不擅长”拐弯”。镜头翻转是一个剪辑动作而非连续运镜,新角色出现需要凭空生成之前不存在的实体,推进特写又是一次运镜变化。三个不连续的视觉跳跃塞在一段连续视频里,模型找不到一条平滑的过渡路径,就崩了。
最终解法: 拆步。先单独生成一张包含神秘人物的静态图作为中间帧,然后让模型从这个锚点往前推。把”从A直接跳到C”变成”A→B→C”,每一步都是模型能理解的小幅变化。
认知: 视频延伸不是剪辑工具,它是一个”续写”工具。就像让AI续写小说一样,你不能指望它在一段话里同时完成场景切换、引入新角色、改变叙事视角。一步一步来。
过渡帧:镜头组之间的”视觉胶水”
不同镜头组之间画风不一致是必然的——毕竟每组是独立生成的。硬切会很突兀。
我的做法是在两个镜头组之间插入一个2秒的过渡视频:用ComfyUI生成一张风格介于两组之间的静态图,再用即梦修一下一致性,最后用Seedance把这张图转成2秒的短视频。这2秒就是视觉上的缓冲区,观众的眼睛有时间适应风格变化。
成本很低,但效果显著。
分段制作时,画面外的一致性容易被忽略
当一个镜头因为动作太复杂需要分段生成时,用上一段的尾帧当下一段的首帧是基本操作。但这只能保证画面内可见元素的连续性——角色的姿势、道具的位置、背景的构图。
画面外的东西就不一定了。比如角色的整体造型细节、场景的光照氛围、色调风格,这些在一张尾帧截图里不一定完整体现。下一段生成时模型可能会自行脑补,结果就是拼起来后发现”感觉哪里不对但说不上来”。
所以分段的时候要额外考虑:画面外的一致性靠什么来锚定?是在prompt里把关键视觉要素写死,还是额外喂一张参考图来锁定风格?这个需要根据具体情况判断,但意识到这个问题本身就能避免很多返工。
我就吃过这个亏:有一段哈维听到敲门去开门,下一个镜头是发现门口的信封。因为上一段的尾帧里哈维的双手不在画面内,我又忘了在prompt里强调他手里拿着煤油灯——结果下一个镜头煤油灯就凭空消失了。模型很诚实:尾帧里没有的东西,它就当不存在。


起始帧和Prompt会”打架”
用了起始帧(First Frame)之后,prompt里严禁重复描述时间、地点、场景这些已经在画面里体现了的信息。否则模型会试图同时满足图像信息和文字信息,两边对不上就会导致机位扭曲、场景错乱。
起始帧已经告诉模型”在哪里”了,prompt只需要告诉它”做什么”。
角色表情:用生理反应替代形容词
写”哈维震惊地看着信”,AI会给你一个瞪大眼睛张大嘴的表情包。
写”哈维的瞳孔微微收缩,身体几乎不可察觉地僵硬了一瞬”,你会得到一个克制的、电影感的反应。
AI对形容词的理解是”越强烈越好”,但对生理描述的理解是具体的、可执行的。想要微妙的表演,就用微妙的指令。
Seedance风格漂移
这个坑比较隐蔽。同样的prompt和参数,隔几天生成的视频风格可能完全不同——因为Seedance的后端会静默更新模型。
解法: 用参考视频功能。把之前满意的视频片段作为风格参考喂进去,比纯靠prompt描述风格稳定得多。
知道什么时候该绕路
这条可能是最重要的经验。
当你发现反复修改prompt、换参考图、调参数,结果依然不对的时候——停下来。不要较劲了。很多时候问题不在你的描述,而在模型本身的能力边界。
这时候该做的不是继续在prompt上死磕,而是退一步想:能不能从镜头设计上绕过去?能不能改一下剧本让这个动作不需要出现?能不能靠剪辑手法遮掉?
我在制作过程中有好几个镜头都是这样解决的。原本设计的动作AI做不出来,最终靠简化动作、改变机位、或者直接砍掉这个镜头用剪辑衔接来替代。成片效果反而更好——因为你不再跟模型的短板较劲,而是扬长避短。
AI视频制作的核心能力,不是写出完美的prompt,而是知道什么时候该换条路走。
一些反思
做完EP01之后,我对AI视频制作的现状有了比较清醒的认识:
能做什么: 氛围、光影、场景构建,这些AI已经做得非常好了。1920年代的煤气灯街道、昏暗的古董店、雨夜的雾气——Seedance出的画面质感是真的能打。
做不了什么: 精确的物理交互、复杂的多步动作、角色之间的互动。这些仍然需要人类用剪辑技巧来弥补。
最重要的认知: AI视频生成不是”输入prompt→输出成片”的魔法。它更像是一个需要你深度参与的协作工具。你需要理解它的能力边界,把复杂任务拆解成它能处理的单元,然后用剪辑把这些单元组装起来。
某种意义上,这跟传统影视制作的逻辑是一样的——没有哪个镜头是一次拍成的,都是拆开拍再剪到一起。AI只是把”拍摄”这个环节的门槛降到了几乎为零,但”导演”和”剪辑”的能力依然是人类的工作。
还有一个趋势性的判断:未来AI视频创作可能会从”Prompt时代”进入”Reference时代”。自然语言描述画面终究是一种有损压缩,而参考图/参考视频是直接在视觉空间里传递信息,带宽高得多。Seedance的全能参考模式已经在这个方向上迈出了一步。未来的核心能力可能不是写prompt,而是”策展”——知道什么样的参考素材能最高效地引导模型。
EP01已经完成了,感兴趣的可以去看看成片:
[三天爆肝 AI生成克苏鲁悬疑短片|他收到一封不该出现的信(序章)]
如果你也在尝试用AI做视频,欢迎评论区交流踩坑经验。毕竟这个领域现在还是蛮荒时代,大家都在摸着石头过河。




